Dokumentensouveränität beginnt beim Dokument – und dort liegt das Problem. Ich habe einen Traum. Keinen großen, keinen politischen. Einen technischen.
Dass in Deutschland wieder Software geschrieben wird, die sinnvoll Dokumente erzeugen lässt. Dass jemand denkt, ein anderer finanziert – und die Nutzer endlich arbeiten können, statt Formatvorlagen zu reparieren.
Das klingt utopisch. Es ist das Gegenteil. Denn es hat schon einmal funktioniert.
250 Bytes statt 35.000
In den 1980er Jahren baute ein Freiburger Mittelständler namens kühn&weyh ein Textsystem, das einer einfachen Regel folgte: Der Autor schreibt den Inhalt. Das System kümmert sich um die Darstellung.
Das System hieß M/TEXT. Ein Geschäftsbrief darin war 250 Bytes groß. Derselbe Brief in Microsoft Word: 35.000 Bytes. Also Faktor 140. Der Unterschied ist dabei nicht Zufall. Er ist Konstruktionsprinzip.
M/TEXT trennte, was heute verschmolzen ist: Inhalt und Layout. Was in der Datei stand, war Text. Nur Text. Die Formatierung – Briefkopf, Schriftart, Seitenränder, Faltmarken – fügte das System erst bei der Ausgabe hinzu. Also nicht bei der Speicherung. Folglich war die Datei auf der Platte reiner Inhalt. Hundert Prozent Nutzlast.
Insgesamt 800 Großkunden nutzten dieses System. Darunter die Münchener Rück, der ADAC, alle Berufsgenossenschaften und der Deutsche Sparkassenverlag. Weltweit vertrieb Cincom Systems das Produkt unter dem Namen MANTEXT – nicht weil es billig war, sondern weil es etwas konnte, das kein anderes Produkt konnte. Tatsächlich hatte kühn&weyh doppelt so viele Nutzer wie die IBM mit Text/370. Ein Mittelständler mit weniger als hundert Mitarbeitern schlug also den größten IT-Konzern der Welt. Nicht durch Marketing. Sondern durch ein Prinzip.
Was die Trennung ermöglichte
Die Kunden kamen nicht wegen der Trennung. Vielmehr kamen sie wegen dem, was die Trennung ermöglichte.
Der ADAC beispielsweise verschickte Millionen Briefe an Mitglieder. Branchendurchschnitt für Serienbriefe: ein Prozent Rücklauf. Mit M/TEXT hingegen: bis zu vierzig Prozent. Faktor vierzig. Denn M/TEXT konnte personalisieren – hunderttausend Briefe, jeder anders, jeder persönlich, jeder korrekt formatiert. Ohne dass ein Mensch am Layout eines einzigen Briefs gearbeitet hätte.
Aus M/TEXT und der Grafiksprache M/GRAF entwickelte sich schließlich M/OMS – ein Output-Management-System, das ich mitentwickelt habe. Es läuft seit 39 Jahren. Störungsfrei. Nicht weil es perfekt ist, sondern weil es das richtige Prinzip umsetzt: Was nicht im Dokument steckt, kann nicht kaputtgehen. Das ist Dokumentensouveränität in Reinform.
Vergleichen Sie das einmal mit Ihrem Word-Dokument von 2005. Öffnen Sie es in Word 2024. Zählen Sie die Formatierungsfehler. Fragen Sie sich, warum die eingebettete Excel-Tabelle nicht mehr funktioniert. Und dann fragen Sie sich, warum ein System aus den Achtzigern problemlos läuft – während Ihr Dokument von vor zwanzig Jahren es nicht tut.
Dokumentensouveränität: Was verloren ging
Die Ideen waren da. Produkte ebenso. Und auch die Kunden fehlten nicht. Was jedoch fehlte, war die Entscheidung, den eigenen Weg weiterzugehen.
kühn&weyh ließ den Nachfolger sterben, weil der eigene Vertrieb sein Produkt schützte. Marco Börries wiederum verkaufte StarDivision an Sun, weil er in Deutschland keine Partner fand – daraus wurde OpenOffice, dann LibreOffice. Und in Neustadt an der Weinstraße entwickelte die SER zeitbezogene Speicherung, die Amazon heute als S3 Glacier verkauft.
Stück für Stück verschwand die Unabhängigkeit. Allerdings nicht durch feindliche Übernahme und auch nicht durch technische Unterlegenheit. Sondern durch Entscheidungen, die kurzfristig vernünftig und langfristig fatal waren.
Heute nutzt deshalb jedes deutsche Unternehmen Microsoft Word. Speichert in einer amerikanischen Cloud. Verwaltet den Ballast mit einem DMS, das nur existiert, weil die Dokumente zu komplex geworden sind. Und bezahlt für all das – in Lizenzen, in Speicher, in Migrationskosten, in verlorener Dokumentensouveränität.
80 Prozent Ballast: Warum Dokumentensouveränität messbar ist
In meinem neuen Buch „Nutzlast – Was Ihre Dokumente wirklich transportieren“ habe ich vermessen, was niemand vermisst: den tatsächlichen Inhalt von Unternehmensdokumenten.
Das Ergebnis, quer durch Branchen und Unternehmensgrößen: Typischerweise 80 Prozent Ballast. Dabei handelt es sich um Layout-Informationen, XML-Strukturen, Editor-Artefakte, eingebettete Themes und Revisionsdaten – also alles Dinge, die kein Leser braucht und kein Geschäftsprozess nutzt.
Bei einem Unternehmen mit 1.000 Mitarbeitern summiert sich das auf geschätzte 2,3 Millionen Euro pro Jahr. Wohlgemerkt nicht für den Inhalt – sondern für die Verpackung.
Zudem ist die Methode in dreißig Minuten reproduzierbar: Zehn DOCX-Dokumente in ZIP umbenennen, entpacken, den reinen Textinhalt messen, durch die Dateigröße teilen. Die Zahl wird zwischen 3 und 25 Prozent Nutzlast liegen. Wahrscheinlich näher an 10.
Warum Dokumentensouveränität jetzt möglich ist
40 Jahre nach M/TEXT ist die Frage, die kühn&weyh richtig beantwortete, wieder die richtige Frage: Was braucht der Inhalt? Und was braucht die Darstellung? Und warum müssen beide in derselben Datei stecken?
Die Trennung ist technisch einfacher denn je. Markdown, Pandoc, Git, Template-Engines – alles Open Source, alles verfügbar. Dennoch fehlt nicht die Technologie. Was vielmehr fehlt, ist das Bewusstsein, dass es einen Rückweg gibt. Und Unternehmer, die diesen Weg gehen.
Vor allem für KI-Anwendungen wird das Thema existenziell: Sprachmodelle arbeiten mit Tokens. Jeder Token kostet Geld. 80 Prozent Ballast bedeutet folglich: 80 Prozent der Token-Kosten entfallen auf Information, die keine ist. Wer also seine Dokumente entschlackt, bevor er KI darauf loslässt, spart nicht nur Speicher – er spart bei jedem einzelnen API-Call.
Der Traum: Dokumentensouveränität, konkret
Was ich mir wünsche, ist keine Rückkehr zu M/TEXT. Die Welt hat sich weitergedreht. Aber das Prinzip – Inhalt und Darstellung trennen, Ballast eliminieren statt verwalten, die Anforderung hinterfragen statt das nächste Werkzeug kaufen – dieses Prinzip ist heute aktueller als je zuvor.
Zunächst müsste jemand denken: ein Architekt, der Dokumentenerzeugung von Grund auf neu entwirft. Leicht. Sicher. Souverän. Ohne die 47 XML-Dateien, die in jeder DOCX-Datei stecken.
Dann müsste jemand finanzieren: ein Investor, der versteht, dass Dokumentensouveränität kein Schlagwort ist, sondern ein Markt. Dass 80 Prozent Ballast eine Geschäftsmöglichkeit sind, keine Naturkonstante.
Und die Nutzer – die könnten endlich arbeiten. Statt Formatvorlagen zu reparieren, Serienbriefe zu debuggen oder Kompatibilitätsprobleme zu googeln.
Es gelang uns damals. Es gelänge uns heute wieder. Dokumentensouveränität ist keine Utopie – man muss nur die Frage stellen.
Das Buch – und die sechs anderen
„Nutzlast“ ist Buch 6 der KI-Macherreihe 2026 – sieben Bücher, geschrieben vom Macher für Macher. Die Leitfrage der Reihe: Wer steuert die Veränderung – das Werkzeug oder der Mensch, der es einsetzt?
Jedes Buch steht für sich. Wer mehrere liest, erkennt die Verbindungen:
Greenfield – Das Fundament. Vier Stufen: Bevor etwas Neues auf Bestehendes gestapelt wird, stellt sich die Frage, ob das Bestehende überhaupt die richtige Basis ist.
Managed Services richtig verstehen – Die Betriebslücke. Was ein Provider verspricht und was er im laufenden Betrieb liefert – dazwischen liegt das Risiko.
Das Helferlein-Paradox – Das Rechercheur-Modell. KI recherchiert, der Mensch entscheidet. Das deutschsprachige Grundlagenwerk zur KI-Rolle in der IT-Entscheidung.
The Little Helper Paradox – Das Rechercheur-Modell im internationalen Kontext.
Plausible Lügen – Datenqualität als Entscheidungsrisiko. Was passiert, wenn die Daten fehlerhaft sind – und die KI trotzdem ein überzeugendes Ergebnis liefert.
Nutzlast – Die Ballast-Ratio. 80 Prozent Ballast in Ihren Dokumenten, messbar, bezifferbar, vermeidbar. Dieses Buch.
Ordnungsenergie(in Arbeit) – Warum jede Integration laufend Energie braucht und Go-Live kein Endpunkt ist.
Was die Bücher verbindet
Die Ballast-Ratio aus Nutzlast liefert dabei den Maßstab, mit dem Ordnungsenergie Integrationsarchitekturen bewertet. Gleichzeitig schärft die Warnung vor plausiblen Lügen den Blick für KI-Ergebnisse, die überzeugend aussehen und trotzdem falsch sind. Und der Greenfield Approach liefert schließlich die Methode, um aufgelaufene Entropie auf null zu setzen, statt sie endlos zu verwalten.
„Nutzlast – Was Ihre Dokumente wirklich transportieren“ ist erhältlich als Taschenbuch bei Amazon (ISBN 978-3-96459-037-4, €24,99) und als Kindle-Edition (€9,99). Für alle, die Dokumentensouveränität nicht nur fordern, sondern messen wollen.
Wer den Ballast in seinem Unternehmen messen will, bevor er das Buch liest: Die Methode steht in Kapitel 3. Dreißig Minuten. Zehn Dokumente. Eine Zahl.
Michael Schmid ist Physiker, Principal Consultant und Eigentümer der it-dialog e.K. in Stuttgart. Er arbeitet seit 1985 in der Softwareentwicklung und hat die Dokumententechnologie von M/TEXT über Output Management bis zur heutigen Cloud-Architektur von innen erlebt.
20. März 2026. Gestern auf der Leipziger Buchmesse wurde für mich sehr greifbar, wie präsent das Thema IT-Abhängigkeit inzwischen in vielen Gesprächen mitschwingt — von Kanälen bis Entscheidungslogik.
Die Hallen wirkten wie ein dicht getakteter Marktplatz für Ideen, Expertise und Handwerk. Ich habe den direkten Austausch mit Menschen gesucht, die Inhalte bauen: Autorinnen und Autoren, die ihre Werke eigenständig präsentieren und ihre Reichweite selbst organisieren. Die Gespräche waren klar und fachlich präzise. Diese Nähe zwischen Urheber und Leser schafft Substanz und Tempo.
Sprache als Werkzeug der Architektur
In einer ruhigeren Ecke traf ich einen schwedischen Autor. Nach wenigen Sätzen waren wir bei einem Thema, das Literatur und IT gleichermaßen betrifft: Sprache als Denkwerkzeug. Seine Kurzform war treffend: Die Grenzen unserer Sprache bilden die Grenzen unserer Welt. Als Physiker und IT-Consultant nehme ich das sehr wörtlich. In der Unternehmensarchitektur und in der Enterprise Architecture wird Komplexität über Begriffe, Modelle und Schnittstellen handhabbar. Präzise Sprache führt zu präzisen Architekturentscheidungen, sauberen Verantwortlichkeiten und belastbaren IT-Landschaften. Genau dort beginnt digitale Souveränität: bei klaren Definitionen, klaren Verträgen und klaren Systemgrenzen.
Ein Markt im Wandel: Sichtbarkeit als Eigenleistung
Der Buchmarkt zeigt 2026 eine klare Verschiebung: Sichtbarkeit entsteht über Eigenleistung, über Rhythmus und über saubere Distribution. Verlage, Bibliothekslogik und gewohnte Vermarktungswege ordnen sich neu. Für Autoren und Unternehmen bedeutet das: Kanäle werden zur Infrastruktur. Wer sie betreibt, steuert Tempo, Botschaft und Feedbackschleifen.
Diese Mechanik ist in der IT vertraut. Digitale Souveränität entsteht, wenn Organisationen ihre kritischen Abhängigkeiten transparent machen und ihren Einflussbereich aktiv erweitern. Inhalte gehören dabei zum Werkzeugkasten: Sie schaffen gemeinsame Begriffe, reduzieren Interpretationsspielräume und beschleunigen Entscheidungen.
Das Experiment: Fünf Fachbücher in 62 Tagen
Aus dieser Dynamik wurde ein Sprint mit sehr klarem Ziel: IT-Abhängigkeiten so greifbar zu machen, dass Entscheider sie priorisieren und strukturiert abbauen können. Ergebnis: fünf Fachbücher in 62 Tagen. Jedes Buch adressiert eine konkrete Abhängigkeit, jeweils mit Methoden, Prüffragen und Umsetzungslogik.
Der rote Faden ist das systematische Finden von GAPs. Eine GAP-Analyse liefert dafür die operative Grundlage: Ist-Zustand, Soll-Zustand, Abweichung, Risiko, Aufwand, Reihenfolge. In der Praxis entscheidet diese Klarheit darüber, ob Maßnahmen Budgets binden oder echte Handlungsfähigkeit erzeugen.
Die sechs Typen der IT-Abhängigkeit
Für belastbare Entscheidungen braucht es ein klares Raster. Die Buchreihe arbeitet mit sechs Abhängigkeitstypen, die in Projekten immer wieder als Kostentreiber, Risikotreiber oder Bremsklotz auftauchen:
Vendor Lock-in: Die Bindung an proprietäre Technologien eines einzelnen Herstellers erschwert den Wechsel und treibt langfristig die Kosten.
Provider-Abhängigkeit: Die Konzentration auf spezifische Cloud-Anbieter oder Managed Service Provider schränkt die Flexibilität bei Preisänderungen oder Service-Level-Anpassungen ein.
KI-Abhängigkeit: Die wachsende Nutzung von KI-Modellen führt zu einer neuen Form der Bindung an Token-Preise und Black-Box-Algorithmen.
Personenabhängigkeit: Das Konzentrieren von exklusivem Expertenwissen auf wenige Individuen stellt ein erhebliches Betriebsrisiko dar.
Architektur-Abhängigkeit: Historisch gewachsene, starre Strukturen verhindern die Adaption moderner Geschäftsprozesse.
Integrations-Abhängigkeit: Eine zu enge Kopplung zwischen Systemen führt dazu, dass Änderungen an einer Stelle unvorhersehbare Auswirkungen auf die gesamte Landschaft haben.
Diese Kategorien sind als Arbeitsinstrument gedacht. In Workshops, Reviews und Architektur-Gremien bringen sie Diskussionen zügig auf prüfbare Fakten: Wo liegt die Abhängigkeit, wie groß ist die Wirkung, welche Schritte reduzieren sie messbar.
IT-Abhängigkeit als Thema für alle Unternehmensbereiche
Die in den Büchern behandelten Themen sind für unterschiedliche Rollen innerhalb einer Organisation von strategischer Bedeutung. Jede Perspektive braucht konkrete Antworten, sobald IT-Abhängigkeit Budget, Risiko oder Lieferfähigkeit beeinflusst.
CFOs finden Ansätze zur langfristigen Kostenkontrolle und zur Vermeidung versteckter Ausgaben durch Lizenzfallen.
Die Revision erhält klare Kriterien für die Bewertung von Compliance-Risiken und die Sicherstellung der Revisionsfähigkeit komplexer IT-Systeme.
Verantwortliche für Managed Services lernen Methoden kennen, um Dienstleister effektiv zu steuern, statt von ihnen gesteuert zu werden.
IT-Strategen erhalten einen Leitfaden, um die digitale Souveränität als Wettbewerbsvorteil zu etablieren.
Jedes Buch bietet praktische Lösungen für diese Zielgruppen und ermöglicht einen direkten Transfer in den Berufsalltag.
Fokus auf das Wesentliche
Der Sprint hatte eine klare Disziplin: Jede Seite musste einen Zweck erfüllen. Dadurch sind Texte entstanden, die schnell in die Anwendung führen: Begriffe, Entscheidungslogik, Checklisten, typische Befundbilder, konkrete nächste Schritte. Das passt zu unserer Arbeit als GAP-finder: Wir suchen die Stellen, an denen Reibung, Kosten und Risiko in der IT-Landschaft versteckt sitzen, und machen sie für Entscheider sichtbar.
Digitale Souveränität ist dabei ein praktisches Ziel. Sie zeigt sich in Wahlfreiheit, belastbaren Datenflüssen, auditierbaren Entscheidungen und einer Architektur, die Änderungen ohne Stillstand verarbeitet. Genau darauf sind die Inhalte ausgelegt.
Am Ende meines Messebesuchs bot sich mir ein Bild, das die Zukunft der Buchwelt symbolisiert. Zahlreiche junge Menschen, aufwendig kostümiert als Manga-Charaktere, bevölkerten die Gänge. Ihr Auftreten zeugte von einer enormen Leidenschaft für Geschichten und Charaktere. Es ist völlig unerheblich, über welche Kanäle oder in welchen Formaten diese Erzählungen konsumiert werden. Die Begeisterung für Inhalte bleibt bestehen, auch wenn sich die Trägermedien und Vertriebswege fundamental wandeln.
Diese Energie lässt sich auf die IT übertragen. Die Leidenschaft für technologische Exzellenz und durchdachte Lösungen ist der Motor für Innovation. Die Formate mögen sich ändern – von der klassischen Dokumentation hin zum interaktiven Architekturmodell oder eben zum fokussierten Fachbuch –, doch der Kern bleibt die Lösung relevanter Probleme.
Zusammenfassung und Ausblick
Die Leipziger Buchmesse 2026 hat für mich vor allem eines bestätigt: Inhalte, Kanäle und Architekturentscheidungen folgen demselben Muster. Wer digitale Souveränität ernst nimmt, braucht Klarheit über Abhängigkeiten, über Verantwortlichkeiten und über die eigene Entscheidungsfähigkeit. Die fünf Bücher aus dem 62-Tage-Sprint sind als Werkzeugkasten dafür gedacht: Sie machen Abhängigkeiten sichtbar, strukturieren die Diskussion und führen in umsetzbare Maßnahmen.
Wenn Sie digitale Souveränität als Management-Thema bearbeiten wollen, starten Sie mit einer sauberen GAP-Analyse Ihrer kritischen Abhängigkeiten — und verankern Sie die Ergebnisse in Ihrer Enterprise Architecture und Ihrer Unternehmensarchitektur-Governance.
SEO Meta-Description:
Fünf Fachbücher in 62 Tagen. Jedes adressiert eine IT-Abhängigkeit. Von CFO bis Revision — welches Buch löst Ihr Problem? Jetzt mehr erfahren.
KI-Systeme halluzinieren. Das ist bekannt. Was weniger bekannt ist: Man kann diese Eigenschaft gezielt ausnutzen. Nicht als Bug – als Waffe. Und nirgends ist das gefährlicher als bei der KI-Sicherheit von Pflegerobotern.
Mein neuer Roman „Plausible Lügen“ – der zweite Band von „Verrat im Hotel der Innovation“ – erzählt genau diese Geschichte. Er ist ab heute als E-Book und in Kürze als Taschenbuch erhältlich.
Aber dieser Beitrag ist keine Buchvorstellung. Er ist eine Warnung. Und eine Einladung, genauer hinzusehen.
KI-Sicherheit bei Pflegerobotern: Das Problem, über das niemand spricht
Pflegeroboter kommen. Die Frage ist nicht ob, sondern wann. Japanische Pflegeheime setzen sie bereits ein. Europa investiert Milliarden. Deutschland diskutiert noch über Regulierung, während andere längst bauen und testen. Die KI-Sicherheit dieser Pflegeroboter? Wird vorausgesetzt. Geprüft wird selten.
Was dabei untergeht: Ein Pflegeroboter lernt aus Daten. Aus Bewegungsmustern, die Pflegekräfte ihm zeigen. Aus Druckwerten, Winkeln, Geschwindigkeiten. Die Maschine optimiert, bis die Zahlen stimmen.
Aber was, wenn die Daten manipuliert sind?
Nicht grob. Nicht offensichtlich. Sondern so subtil, dass das System selbst die Manipulation nicht erkennt – weil es prinzipiell nicht zwischen „richtig“ und „plausibel“ unterscheiden kann. Die Fachwelt nennt das Halluzinationen. Ich nenne es plausible Lügen.
Genau hier liegt die eigentliche Gefahr. Denn eine KI, die plausibel lügt, ist gefährlicher als eine, die offensichtlich versagt. Der offensichtliche Fehler wird gefunden und korrigiert. Die plausible Lüge wird geglaubt – und in die nächste Entscheidung übernommen.
Vertraue nie der KI – vertraue dem Käfig
In meinem Sachbuch „Das Helferlein-Paradox“ habe ich die technischen Grundlagen untersucht. Die zentrale Erkenntnis ist unbequem: Wir können nicht wissen, ob eine KI richtig liegt. Nicht weil die Technik schlecht wäre, sondern weil es prinzipielle Grenzen gibt, die kein Algorithmus überwindet.
Die Konsequenz daraus ist nicht, KI abzulehnen. Die Konsequenz ist, sie einzusperren. In einen Käfig aus Normen, Prüfschleifen und menschlicher Kontrolle. ISO 14971 für Risikomanagement. IEC 62304 für Software-Lebenszyklus. Der EU AI Act, der Hochrisiko-Systeme klassifiziert. Rückkopplungsschleifen, bei denen am Ende immer ein Mensch entscheidet.
Das klingt trocken. Aber es ist der Unterschied zwischen einer Maschine, die hilft, und einer, die tötet. In der Pflege wiegt dieser Unterschied besonders schwer. Hier geht es nicht um fehlerhafte Empfehlungen oder falsche Texte. Hier geht es um Menschen, die sich nicht wehren können – die darauf angewiesen sind, dass die Maschine, die sie berührt, das Richtige tut.
Wer sich auf die Sicherheit von Pflegerobotern verlässt, ohne den Käfig zu verstehen, spielt russisches Roulette mit Menschenleben.
Was „Plausible Lügen“ über KI in der Pflege erzählt
Dr. Friedrich Holstein leitet ein Innovationscluster in Norddeutschland. Sein Team entwickelt Agnes, einen Pflegeroboter, der alles verändern könnte. Der Käfig steht, die Normen sind umgesetzt, die Dokumentation ist lückenlos.
Dann entdeckt eine Ingenieurin, dass etwas nicht stimmt. Nicht in den Zahlen – die sind perfekt. Sondern in der Art, wie Agnes sich bewegt. Die Eleganz fehlt. Die Menschlichkeit. Etwas, das kein Sensor misst, kein Protokoll erfasst – und das die gesamte Sicherheit des Pflegeroboters in Frage stellt.
Sie kennt Agnes seit zwei Jahren. Sie hat jede Iteration begleitet, jeden Fortschritt, jeden Rückschlag. Am Anfang war Agnes unbeholfen – mechanisch, abgehackt. Dann wurde sie flüssiger, natürlicher, menschlicher. Nicht weil jemand sie programmiert hatte, sondern weil sie gelernt hatte. Von Pflegekräften, von tausenden Stunden Trainingsdaten.
Und jetzt fehlt plötzlich das, was Agnes besonders machte.
Holstein steht vor einem Problem, das größer ist als jeder Saboteur: Niemand glaubt ihm. Nicht weil die Beweise fehlen. Sondern weil alle dem System vertrauen. Die Zahlen sind grün. Die Protokolle stimmen. Alles ist normkonform. Nur das Gefühl einer erfahrenen Ingenieurin sagt: Hier stimmt etwas nicht.
Warum ein Thriller über Pflegeroboter-Sicherheit?
Weil Fachbücher die Falschen erreichen. Wer ISO 14971 liest, weiß bereits, dass KI-Sicherheit wichtig ist. Aber die Entscheidungen über den Einsatz von Pflegerobotern treffen Menschen, die keine Normen lesen. Politiker, Investoren, Geschäftsführer von Pflegeheimen.
Diese Menschen erreicht man mit Geschichten. Mit der konkreten Vorstellung, was passiert, wenn der Käfig nicht hält. Mit einer Erzählung, die zeigt, dass KI-Sicherheit bei Pflegerobotern kein abstraktes Thema ist, sondern über Leben und Würde entscheidet.
„Plausible Lügen“ ist Fiktion. Aber die technischen Grundlagen sind real. Die Normen existieren. Die Schwachstellen existieren. Und die Frage, ob wir einer KI vertrauen dürfen, die wir nicht verstehen, wird mit jedem Tag drängender.
Der Hintergrund ist real
2016 wurde eine Standortanalyse für das erste private deutsche Innovationscluster fertiggestellt. Vier Studenten der Hochschule Fresenius untersuchten Rendsburg als Standort. Ergebnis: geeignet. Acht Tage später war das Projekt tot – eine politische Entscheidung zog sechzig Millionen Euro Investitionszusagen über Nacht ab.
Ich weiß das, weil es mein Projekt war. Ich hatte das Innovationscluster konzipiert, die Investoren gewonnen, die Vision entwickelt. Und ich stand da und sah zu, wie alles zusammenbrach. Details finden Sie hier.
Aus diesem Scheitern entstand 2019 der erste Band. Und aus der KI-Revolution, die seitdem stattgefunden hat, entstand Band 2 – ein Thriller über die Frage, was passiert, wenn KI-Sicherheit bei Pflegerobotern versagt. Die Geschichte ist erfunden. Die Kaserne am Nord-Ostsee-Kanal gibt es wirklich. Die Schwebefähre fährt wieder. Die Standortanalyse der Hochschule Fresenius existiert. Und die Frage, die dieser Roman stellt, wird jeden Tag realer.
Erhältlich ab heute
Plausible Lügen – Verrat im Hotel der Innovation, Band 2 Von Michael Schmid
E-Book: 4,99 € – Jetzt bei Amazon kaufen Taschenbuch: In Kürze verfügbar – ISBN 978-3-96459-034-3
Wer die technischen Hintergründe vertiefen möchte: „Das Helferlein-Paradox“ ist als Sachbuch ebenfalls bei Amazon erhältlich – auf Deutsch und als „The Little Helper Paradox“ auf Englisch. Denn wer über KI-Sicherheit bei Pflegerobotern mitreden will, sollte verstehen, warum der Käfig wichtiger ist als die Maschine, die darin sitzt.
KI Managed Service – das klingt nach Vereinfachung. Doch Tiefe ist mühsam. Sie kostet Zeit und verlangt Konzentration. Deshalb wird sie gern vermieden.
Doch in meiner Erfahrung führt genau diese Vermeidung zu dem, was alle vermeiden wollen: unnötige Kosten, unnötige Risiken, unnötige Nacharbeit.
Mein neues Buch „Das Helferlein-Paradox“ entstand aus einer einfachen Frage: Was passiert, wenn ich versuche, für einen KI Managed Service ein Service Level Agreement zu schreiben?
Die Antwort war unbequem. Aber sie hilft, Unnötiges zu vermeiden.
KI Managed Service: Was Sie erwartet
Wenn Sie Entscheidungen verantworten: Sie erfahren, warum die Compliance-Kosten für KI Managed Service in kritischen Anwendungen bei 500.000 bis 800.000 Euro im ersten Jahr liegen können – und warum diese Zahl keine Panikmache ist, sondern eine nüchterne Kalkulation.
Wenn Sie entwickeln oder konstruieren: Sie finden eine Sprache für das, was Sie vermutlich längst spüren. Den Unterschied zwischen einem Industrieroboter, der zuverlässig schweißt, und einem Sprachmodell, das plausibel klingt, aber nicht verlässlich ist. Und Sie finden Argumente für das nächste Gespräch mit jemandem, der meint, „mit KI läuft das doch von selbst“.
Wenn Sie lokale LLM-Infrastruktur aufbauen: Sie verstehen, warum das Researcher-Modell – KI als Werkzeug, nicht als Entscheider – der einzig gangbare Weg für verantwortungsvolle Anwendungen ist. Und was das für Ihre Architekturentscheidungen bedeutet.
Wenn Sie in Technologieunternehmen investieren: Sie lernen, welche Fragen Sie stellen sollten, bevor Sie in ein KI-Startup investieren. Was kann vertraglich zugesichert werden? Was nicht? Wo endet das Versprechen, wo beginnt die Hoffnung?
Wie dieses Buch über KI Managed Service entstand
Ich habe dieses Buch nicht gegen KI geschrieben. Ich habe es mit KI geschrieben. Und ich habe KI gebaut.
Meine Forschung war praktisch: der Entwurf einer LLM-Architektur für AWS. Persönliche Erfahrungen mit OpenAI und Anthropic über Monate hinweg. Versuche mit LMStudio und Ollama in meinem eigenen Lab – lokal, internetunabhängig, unter meiner Kontrolle.
Ich habe Agentensysteme getestet und dabei erlebt, wie sich APIs laufend ändern. Was gestern funktionierte, funktioniert heute anders – oder gar nicht mehr. Ich habe Online-Plattformen wie marblism.com evaluiert, die versprechen, fertige Agentenlösungen bereitzustellen. Und ich habe Microsoft Copilot Studio untersucht, um zu verstehen, wie Enterprise-Anbieter das Thema KI Managed Service angehen.
Jeder dieser Versuche lieferte Erkenntnisse. Nicht immer die erhofften. Aber immer nützliche.
Auch die Hardware-Frage stellte sich konkret. Mein Sohn baut gerne Rechner selbst – er spielt mit den besten verfügbaren Grafikkarten. Wir überlegten, ob er einen Rechner für mein Lab zusammenbauen würde. Also rechnete ich den Bedarf nach: Welche GPU-Speicher brauche ich für lokale Modelle in brauchbarer Größe? Was kostet das? Die Zahlen waren ein weiteres Argument, dieses Buch zu schreiben. Wer über KI-Infrastruktur entscheidet, sollte wissen, was sie wirklich kostet.
Ich wollte wissen, wie sich diese Systeme verhalten, wenn niemand zusieht. Was sie können. Wo sie scheitern. Und ob das, was die Anbieter versprechen, dem entspricht, was ich erlebe.
Die Fähigkeit, Service Level Agreements kritisch zu lesen und zu formulieren, kam nicht aus dem Nichts. Sie entstand durch jahrzehntelange Arbeit an Verträgen bei Kunden – und durch meine eigenen Entwürfe für einen Konzern, der einen Managed Service für kritische Infrastruktur vertraglich absichern musste. Wer einmal versucht hat, Garantien für etwas zu formulieren, das sich nicht garantieren lässt, vergisst diese Erfahrung nicht.
Claude, das Sprachmodell von Anthropic, wurde dabei mein Recherchewerkzeug, Sparringspartner und kritischer Gegenleser. Über Monate hinweg. In hunderten von Gesprächen.
Dabei habe ich genau das praktiziert, was ich im Buch als „Researcher-Modell“ beschreibe: Die KI liefert Material, Perspektiven, Formulierungsvorschläge. Die Entscheidung, was davon stimmt, was brauchbar ist, was veröffentlicht wird – die liegt bei mir.
Das ist keine Einschränkung. Das ist die einzige Arbeitsweise, die in kritischen Kontexten funktioniert.
Zwei Sprachen, drei Kontinente
Die deutschsprachige Ausgabe ist seit Januar 2026 verfügbar – als Kindle, in Kürze als Taschenbuch, und über Tolino im deutschen Buchhandel.
Die englische Ausgabe „The Little Helper Paradox“ erscheint in zwei Wochen. Sie durchläuft gerade den sprachlichen Feinschliff – validiert von einer kanadischen Lektorin, nach demselben Prinzip: KI als Werkzeug, Mensch als Entscheider.
Was mich besonders freut: Das Buch wird aktuell von IT-Profis in Indien gelesen, mit denen ich seit zwanzig Jahren zusammenarbeite. Unsere gemeinsame Erfahrung – was in der Zusammenarbeit zwischen deutschen und indischen Teams funktioniert und was nicht – ist direkt ins Buch eingeflossen. Kapitel 13a zieht die Parallele: Wer gelernt hat, dass erfolgreiche Offshore-Zusammenarbeit explizite Strukturen braucht, wird auch mit LLMs besser arbeiten. Die Verantwortung für klare Aufträge liegt beim Auftraggeber – nicht beim Ausführenden.
Und ja, ich erwarte auch die Auseinandersetzung mit amerikanischen Interessenvertretern. Ein Buch, das fragt, was KI nicht leisten kann, wird nicht überall Applaus ernten. Das ist in Ordnung. Die Fragen bleiben trotzdem richtig.
Was Leser über KI Managed Service sagen
Die ersten Rückmeldungen überraschen mich – in ihrer Bandbreite.
Eine Bibliothekarin schrieb, das Buch habe ihr Aufschluss gegeben, was es im verantwortlichen Entwicklungsumfeld alles zu beachten gäbe. Sie arbeitet nicht in der IT. Aber sie versteht jetzt, welche Fragen gestellt werden müssen.
Ein ehemaliger Schüler von mir – jemand, der jahrelang Beschaffungsentscheidungen in einem hochregulierten Industrieumfeld verantwortete, wo Fehler keine Option sind – formulierte es so:
„Ein ziemlich nahe an Wahnsinn und Ehrlichkeit gezeichnetes Buch. Respekt an deine tiefsinnigen Antworten auf noch ungestellte Fragen.“
Antworten auf noch ungestellte Fragen – das trifft es vielleicht am besten. Dieses Buch versucht nicht, den aktuellen Hype zu bedienen. Es versucht, die Fragen zu formulieren, die in zwei Jahren auf jedem Schreibtisch liegen werden.
Warum KI Managed Service nicht funktioniert
Große Sprachmodelle können beeindruckende Ergebnisse liefern. Aber sie können eines nicht: garantieren, dass das Ergebnis korrekt ist.
Das ist kein Bug. Das ist Systemverhalten.
Und deshalb funktioniert das klassische KI Managed Service-Modell – „Sie zahlen, wir garantieren“ – für LLM-Anwendungen in kritischen Bereichen nicht. Nicht aus technischen Gründen allein. Sondern aus vertraglichen, aus haftungsrechtlichen, aus organisatorischen.
Wer das versteht, kann KI sinnvoll einsetzen. Wer es ignoriert, wird Lehrgeld zahlen. Eine systematische GAP-Analyse hilft, die Lücken zwischen Versprechen und Realität sichtbar zu machen.
Für wen ist dieses Buch?
Für alle, die mit KI arbeiten wollen, ohne die Verantwortung abzugeben.
Für Ingenieure, die wissen, dass Fehler Konsequenzen haben.
Für Entscheider, die verstehen wollen, bevor sie unterschreiben.
Für Investoren, die wissen möchten, was hinter dem Versprechen liegt.
Und für alle, die glauben, dass tiefes Nachdenken keine Zeitverschwendung ist – sondern die einzige Art, Unnötiges zu vermeiden.
Das Helferlein-Paradox: LLM zwischen Versprechen und Verantwortung
Verfügbar als Kindle: Bei Amazon kaufen
Taschenbuch und Tolino: in Kürze
The Little Helper Paradox (Englisch)
Erscheint Februar 2026
Fragen zum Buch oder zu KI Managed Service in Ihrem Unternehmen? Nehmen Sie Kontakt auf.
90% aller Transformationsprojekte verfehlen ihre ursprünglichen Ziele. Diese Statistik ist nicht neu, doch ihre Auswirkungen auf Managed Services werden häufig unterschätzt. In hochverfügbaren Umgebungen – etwa in KRITIS – können Verzögerungen existenzbedrohend sein; das zugrunde liegende Prinzip gilt jedoch für alle Arten von Managed Services, unabhängig von Branche oder Kritikalität.
Die Ursache liegt nicht in mangelnder technischer Kompetenz oder unzureichenden Budgets. Das Problem ist strukturell: Klassische Change-Management-Ansätze versuchen, bestehende Systeme und Organisationen zu verändern. Dieser Ansatz stößt auf organisatorische Widerstände, kulturelle Barrieren und technische Altlasten, die Projekte auf 10+ Jahre ausdehnen können. KRITIS dient in diesem Beitrag als Beispiel – die beschriebenen Vorgehensweisen lassen sich auf alle Managed Services übertragen.
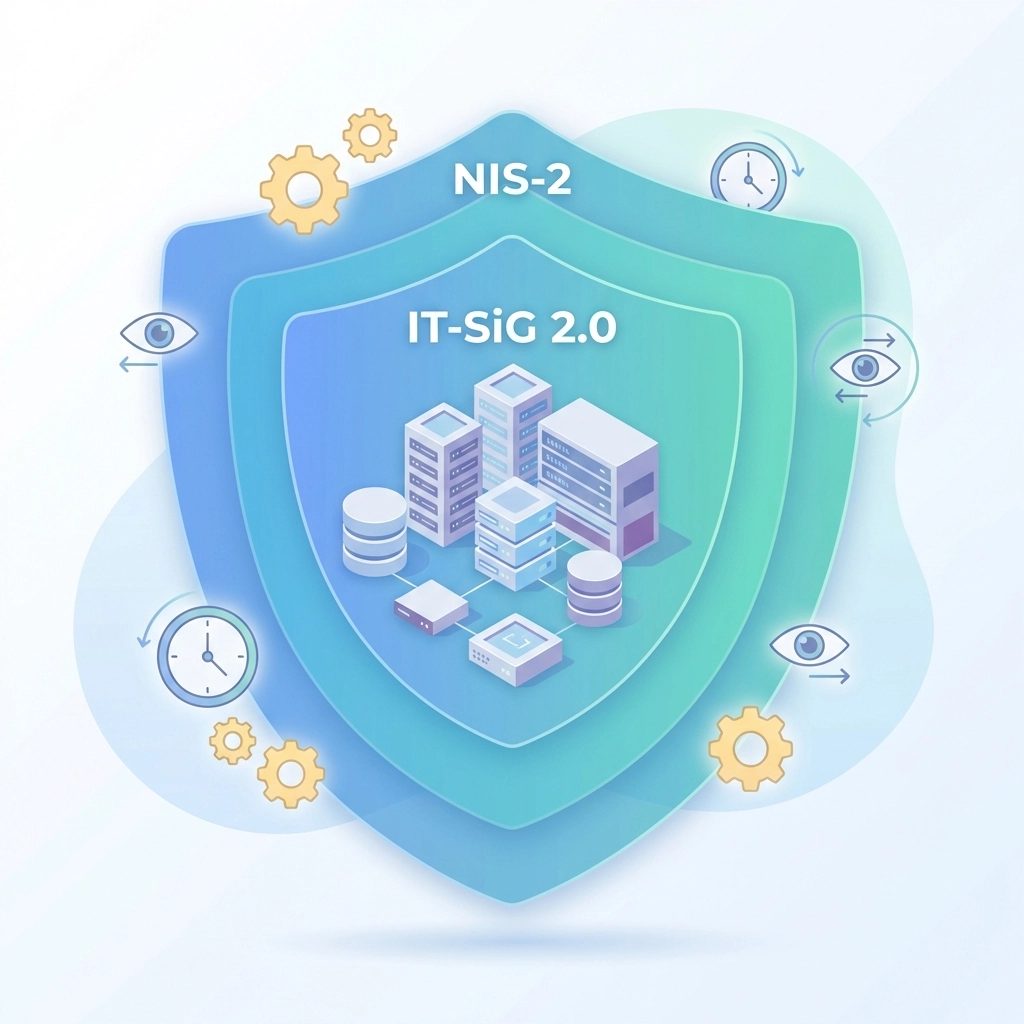
Warum KRITIS-Transformationen besonders komplex sind
Betreiber kritischer Infrastrukturen stehen vor einzigartigen Herausforderungen:
Regulatorischer Druck intensiviert sich: Das IT-Sicherheitsgesetz 2.0 und die NIS-2-Richtlinie verschärfen Compliance-Anforderungen erheblich. Unternehmen müssen nicht nur nachweisen, dass ihre Systeme sicher sind, sondern auch, dass sie kontinuierlich überwacht und verbessert werden.
Zero-Downtime-Anforderung: Kritische Infrastrukturen können nicht einfach „abgeschaltet und neu aufgesetzt“ werden. Jede Änderung muss im laufenden Betrieb erfolgen, was die Komplexität exponentiell erhöht.
Fachkräftemangel verschärft Situation: Qualifizierte IT-Sicherheitsexperten sind rar. Interne Teams sind oft bereits an ihren Belastungsgrenzen und können zusätzliche Transformationsprojekte kaum stemmen.
Technische Altlasten bremsen aus: Viele KRITIS-Betreiber arbeiten mit gewachsenen IT-Landschaften, die über Jahrzehnte entstanden sind. Diese Systeme zu modernisieren gleicht einem chirurgischen Eingriff am offenen Herzen.
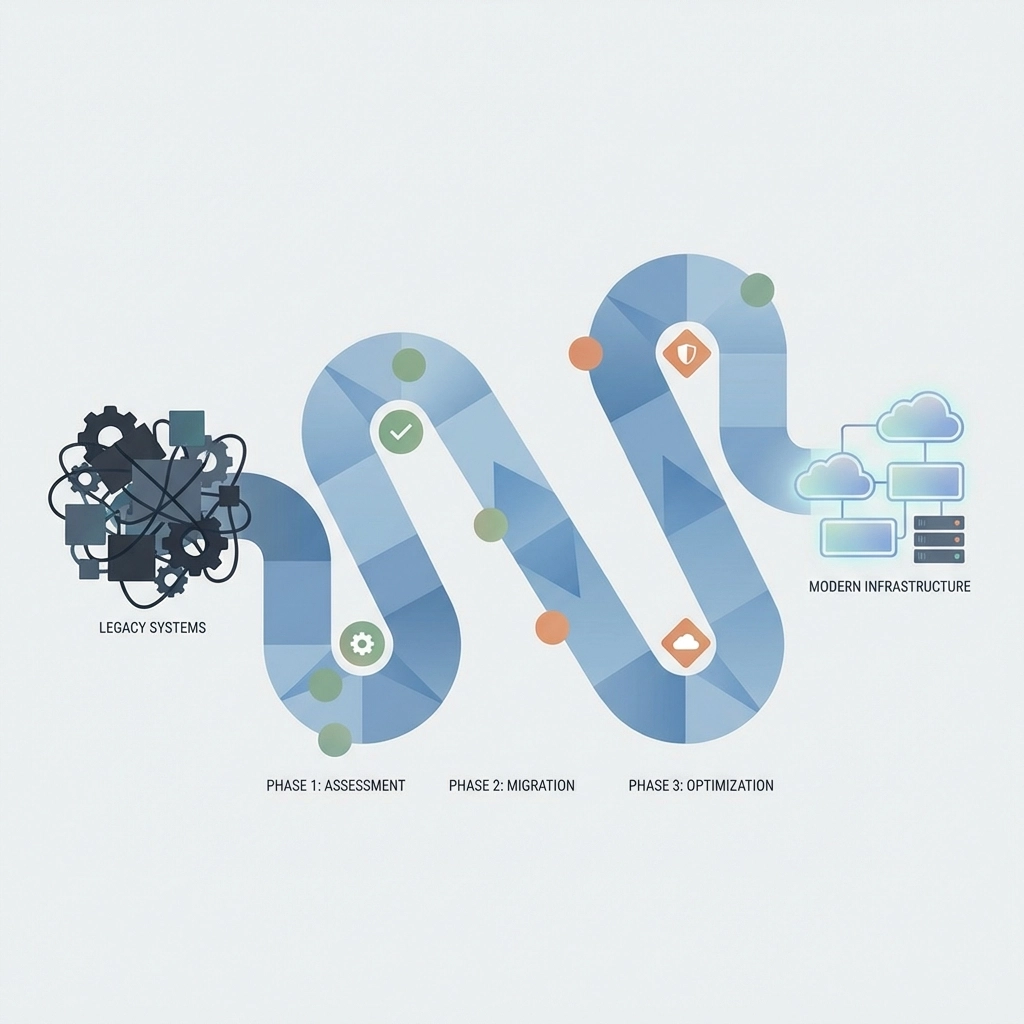
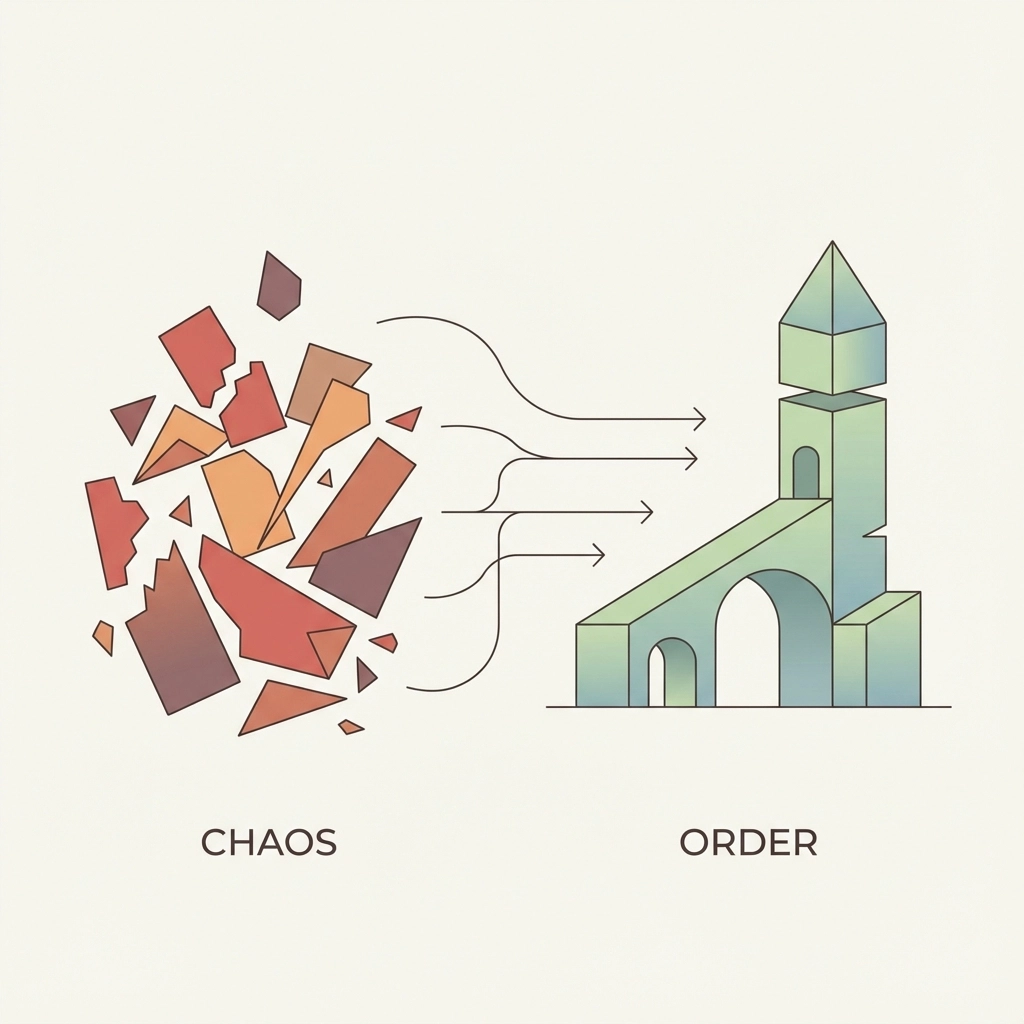
Der Greenfield Approach: Paralleler Aufbau statt Transformation
Der Greenfield-Ansatz kehrt die traditionelle Denkweise um: Anstatt bestehende Strukturen zu verändern, werden parallel neue, moderne Systeme aufgebaut. Die alte und neue Welt koexistieren zunächst, bis die neue Infrastruktur vollständig etabliert ist.
Kernprinzipien des Greenfield-Ansatzes:
Paralleler Aufbau: Neue Systeme entstehen unabhängig von bestehenden Strukturen
Modernste Technologie: Keine Kompromisse aufgrund legacy-bedingter Einschränkungen
Klare Zielvision: Definition des gewünschten Endzustands ohne Rücksicht auf historische Beschränkungen
Stufenweise Migration: Kontrollierter Übergang von alt zu neu
Zeitvorteil: Was bei klassischen Transformationen 10-15 Jahre dauert, kann durch parallelen Aufbau in 2-3 Jahren realisiert werden.
Managed Services: Die strukturelle Marktlücke
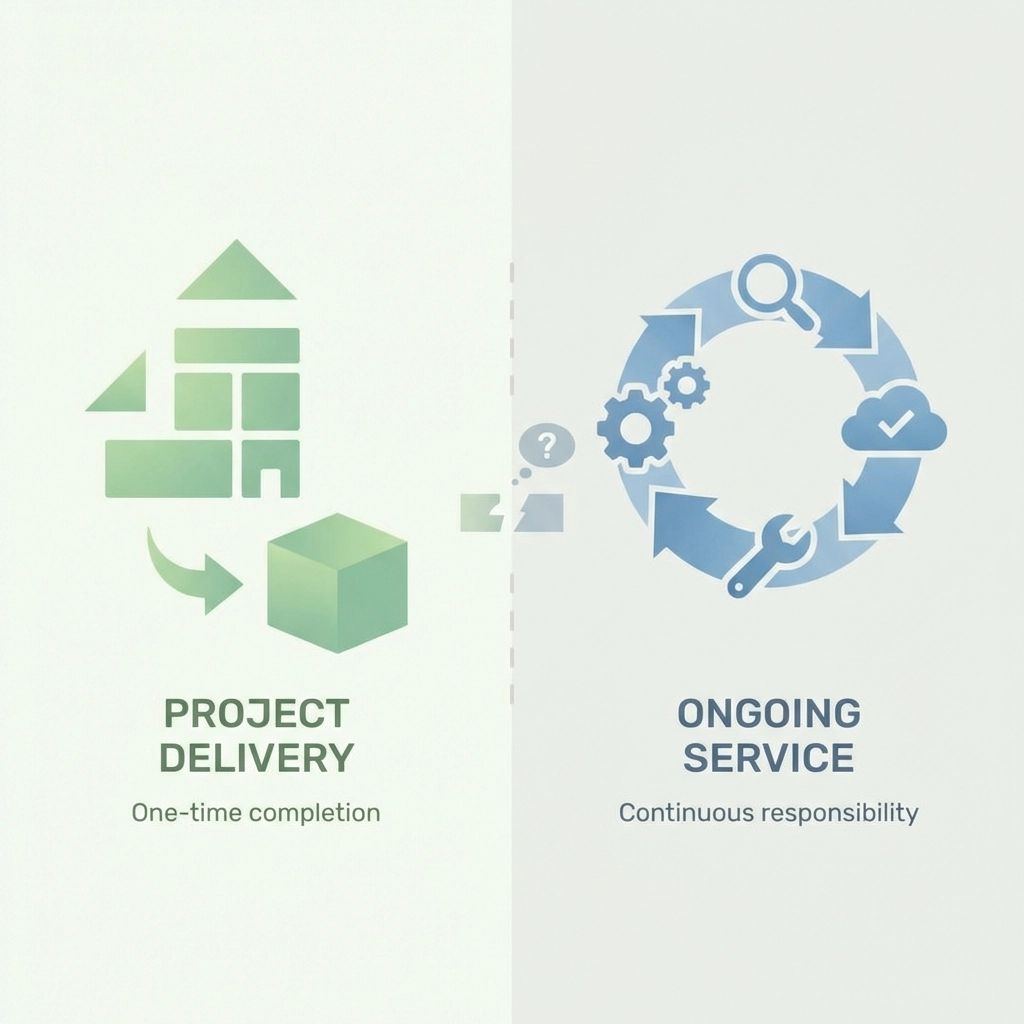
Der Markt zeigt eine auffällige Diskrepanz: Systemhäuser beherrschen Projekte, versagen aber oft beim dauerhaften Betrieb. Diese Lücke betrifft alle Betreiber geschäftskritischer Services – KRITIS ist nur ein prominentes Beispiel.
Projekt vs. Service – Die fundamentalen Unterschiede:
Aspekt
Projektgeschäft
Managed Service
Zielsetzung
Definierter Scope, Abnahme
Dauerhafte Verfügbarkeit
Erfolg
Projekterfolg = Abnahme
Kundenzufriedenheit über Jahre
Kultur
„Wir liefern ab“
„Wir übernehmen Verantwortung“
Geschäftsmodell
Einmaliger Auftrag
Wiederkehrende Umsätze
Risiko
Begrenzt auf Projektlaufzeit
Kontinuierliche Haftung
Das Problem: Viele Anbieter behaupten, Managed Services anbieten zu können, haben aber weder die organisatorischen Strukturen noch die kulturelle Ausrichtung dafür entwickelt.
Praxisfall: Wenn der Vertrag unterschrieben ist, aber niemand liefern kann
Im beschriebenen Fall wurde der vereinbarte Managed Service nach Vertragsunterzeichnung nicht geliefert. Stattdessen versuchte der Anbieter, mit zahlreichen Einzelmaßnahmen das bestehende Vorgehen fortzusetzen und den Dienst wie üblich zu betreuen.
Was geschah:
Operative Tätigkeiten wurden ad hoc verteilt, jedoch ohne klar definiertes Service-Modell
Verantwortlichkeiten und Eskalationswege blieben unklar
Kein nachhaltiges Betriebsmodell (keine expliziten SLAs/SLOs, keine 24/7-Strukturen, keine systematische Continual Service Improvement)
Kein organisatorischer Wechsel vom Projekt- in den Service-Modus
Ergebnis:
Das Ziel, einen klaren Managed Service zu etablieren, wurde verfehlt
Unklare Zuständigkeiten und fehlende Verbindlichkeit führten zu Reibungsverlusten
Der Dienst blieb im alten Betreuungsmuster; der Kunde musste temporär übernehmen
Fazit: Ohne klare Trennung von Projekt und Service entsteht Innovations-Theater statt echter Transformation. Ein Managed Service erfordert ein explizites Operating Model, definierte Rollen (z. B. Service Owner und On-Call), messbare Serviceziele sowie kontinuierliche Verbesserungsprozesse.
Einordnung zur Literatur: Die Beobachtung deckt sich mit den Lehren aus den einschlägigen Büchern zur Service-Transformation: Build und Run müssen organisatorisch getrennt, Verantwortlichkeiten eindeutig zugewiesen und SLAs/SLOs verbindlich verankert werden; erst dann entsteht ein belastbares, skalierbares Service-Modell.
Hinweis auf mein eben erschienenes Buch bei Amazon zum Thema:
Regulatorische Herausforderungen verstärken den Handlungsdruck
Das IT-Sicherheitsgesetz 2.0 und die NIS-2-Richtlinie erhöhen den Druck auf KRITIS-Betreiber erheblich:
Verschärfte Nachweispflichten:
Kontinuierliche Risikobewertung der IT-Systeme
Dokumentierte Incident-Response-Prozesse
Regelmäßige Penetrationstests und Schwachstellenanalysen
Meldepflichten bei Sicherheitsvorfällen innerhalb 24 Stunden
Problematik für interne Teams:
Diese Anforderungen überfordern viele interne IT-Abteilungen. Der Fachkräftemangel verschärft die Situation zusätzlich. Externe Unterstützung wird zur Notwendigkeit.
Warum klassische Transformation hier versagt:
Bei herkömmlichen Change-Projekten dauert es Jahre, bis neue Compliance-Prozesse vollständig implementiert sind. Diese Zeit haben KRITIS-Betreiber nicht mehr.
Projekt vs. Service: Die kulturellen Unterschiede verstehen
Die Unterscheidung zwischen Projekt- und Service-Mentalität ist fundamental und wird oft unterschätzt:
Projektkultur:
„Scope erfüllen und abschließen“
Optimierung für einmalige Leistungserbringung
Erfolg = termingerechte Abnahme
Team löst sich nach Projektende auf
Service-Kultur:
„Verantwortung übernehmen und kontinuierlich verbessern“
Optimierung für langfristige Kundenzufriedenheit
Erfolg = dauerhaft stabile Verfügbarkeit
Team entwickelt sich kontinuierlich weiter
Die Herausforderung: Ein Systemhaus kann nicht einfach per Knopfdruck von Projekt- auf Service-Modus umschalten. Dies erfordert fundamentale organisatorische und kulturelle Veränderungen.
Handlungsempfehlungen für KRITIS-Betreiber
1. Greenfield-Potentiale identifizieren:
Analysieren Sie, welche Ihrer IT-Services parallel neu aufgebaut werden können, anstatt bestehende Systeme zu transformieren.
2. Service-Fähigkeit bei Anbietern prüfen:
Stellen Sie nicht nur die Frage „Können Sie das Projekt?“, sondern „Können Sie dauerhafte Verantwortung übernehmen?“
Prüfkriterien für echte Service-Fähigkeit:
24/7-Organisationsstrukturen vorhanden?
Referenzen für mehrjährige Service-Verträge?
Kontinuierliche Verbesserungsprozesse etabliert?
Service-Level-Agreements mit finanzieller Haftung?
3. Regulatorische Compliance als Service-Anforderung definieren:
Machen Sie NIS-2- und IT-SiG-Compliance zu einem expliziten Bestandteil Ihrer Service-Ausschreibungen.
4. Parallele Strukturen nutzen:
Nutzen Sie den Greenfield-Ansatz, um moderne, compliance-konforme IT-Services aufzubauen, während die bestehende Infrastruktur weiterläuft.
Fazit: Geschwindigkeit durch Parallelität
Der traditionelle Ansatz, bestehende IT-Infrastrukturen schrittweise zu modernisieren, ist für Betreiber geschäftskritischer Managed Services nicht mehr zeitgemäß. Regulatorischer Druck, Fachkräftemangel und die Komplexität gewachsener Systeme machen klassische Transformationsprojekte zu einem Risiko – in KRITIS besonders sichtbar, aber keineswegs exklusiv.
Der Greenfield-Approach bietet eine bewährte Alternative: Durch parallelen Aufbau moderner, compliance-konformer Services können Organisationen ihre Ziele in Jahren statt Jahrzehnten erreichen.
Entscheidend ist dabei die Auswahl der richtigen Partner. Nicht jeder Anbieter, der Projekte beherrscht, kann auch echte Managed Services liefern. Die Unterschiede in Kultur, Organisation und Geschäftsmodell sind fundamental.
Die zentrale Frage für Betreiber lautet:
Können Sie es sich leisten, weitere 10 Jahre auf die Transformation zu warten – oder ist es Zeit für einen parallelen Neuanfang?
Sie stehen vor ähnlichen Herausforderungen in Ihrer kritischen Infrastruktur? Lassen Sie uns über konkrete Lösungsansätze sprechen: www.it-dialog.com
Eine Analyse der systematischen Versagensmuster externer IT-Expertise zeigt: Nicht selten dominiert Innovationstheater – glänzende Präsentationen ohne belastbare Umsetzung. Das Problem ist nicht der Einsatz externer Berater an sich, sondern wie sie ausgewählt, eingesetzt und kontrolliert werden. Wenn alle sagen „geht nicht“ und McKinsey aufgibt – dann braucht es einen anderen Ansatz.
Die ernüchternde Realität: Zahlen ohne Rhetorik
Die Standish Group erhebt seit 1994 Daten zu IT-Projekterfolgen mit ernüchternden Ergebnissen:
Nur 9% der IT-Projekte in Großunternehmen sind erfolgreich (pünktlich, im Budget, volle Funktionalität)
52,7% der Projekte überschreiten das Budget oder reduzieren den Umfang
31,1% werden komplett abgebrochen
Durchschnittliche Kostenüberschreitung: 189% des ursprünglichen Budgets
Diese Zahlen bedeuten: In neun von zehn IT-Projekten bei Großunternehmen stimmt am Ende entweder das Budget nicht, der Zeitplan nicht, der Funktionsumfang nicht – oder das Projekt wird komplett abgebrochen.
Die Pegasystems-Studie 2025 quantifiziert die jährlichen Verluste durch technische Schulden: 370 Millionen USD Gesamtverlust pro Unternehmen und Jahr.
Dokumentierte Katastrophen: Was wirklich schiefging
National Grid vs. Wipro: Über 1 Milliarde USD Schaden
National Grid USA wollte ihre Back-Office-Systeme auf SAP migrieren. Budget: 290 Millionen USD. Sie wechselten von Deloitte zu Wipro – Hauptgrund: Kostensenkung.
Wipros Behauptung: „Well-established SAP practice“ für Utilities. Die Realität: Wipro hatte faktisch keinerlei Erfahrung mit SAP-Implementierungen für US-regulierte Versorgungsunternehmen.
Die Folgen nach Go-Live:
Mitarbeiter wurden falsch bezahlt oder gar nicht
8 Millionen USD Überzahlungen nie zurückgeholt
15.000+ Lieferantenrechnungen nicht verarbeitet
Buchungsabschluss: von 4 Tagen auf 43 Tage
Stabilisierungskosten: 30 Millionen USD pro Monat
Gesamtschaden: Über 1 Milliarde USD
Weitere dokumentierte Millionenschäden
Unternehmen
Jahr
Schaden
Kernproblem
Revlon
2018
64 Mio. USD
Keine SAP-Erfahrung, falscher Systemwechsel
MillerCoors vs. HCL
2014-2017
100 Mio. USD
80 Defekte beim ersten Rollout
Lidl
2011-2018
500 Mio. EUR
SAP-Standard passte nicht zu Geschäftslogik
US Air Force ECSS
2005-2012
1+ Mrd. USD
Kein klares Ziel, kein Wille zur Umsetzung
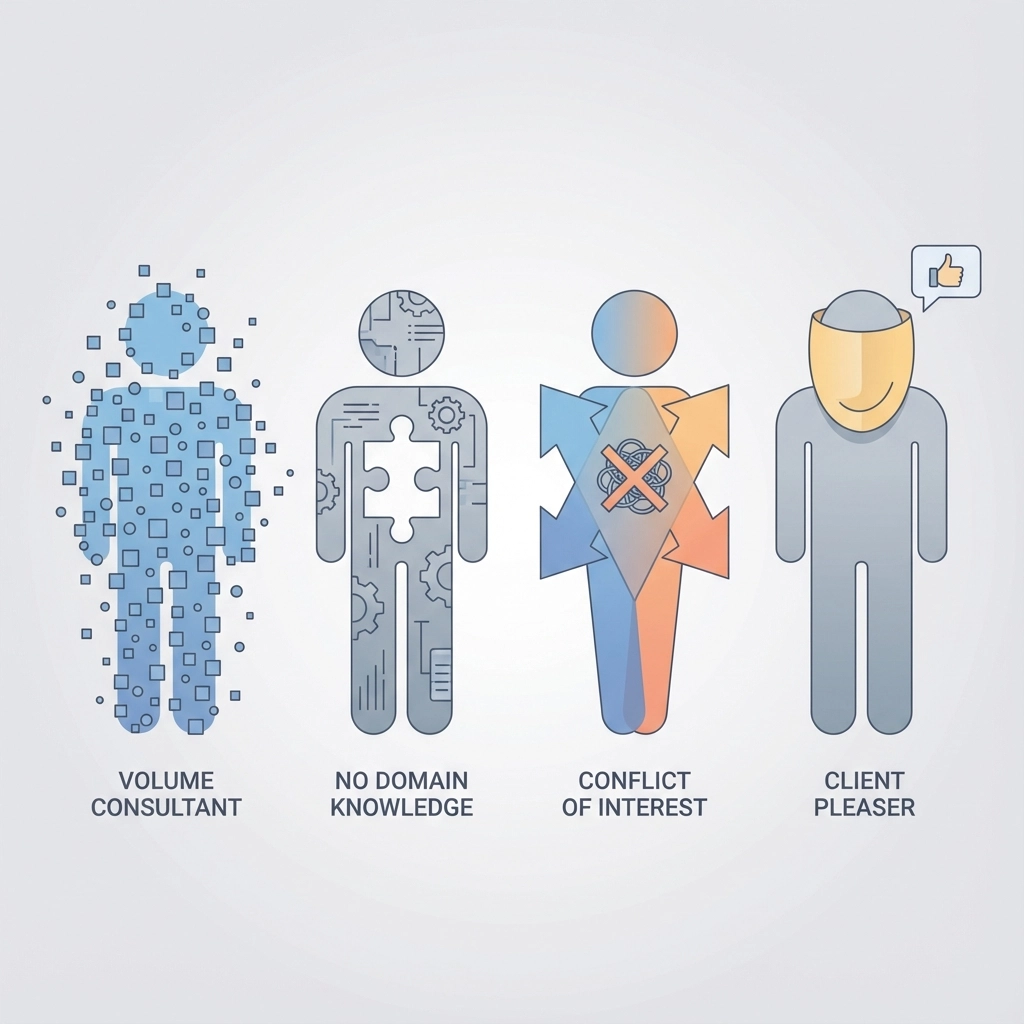
Die vier Typen externer Expertise, die regelmäßig scheitern
Typ 1: Der Offshore-Volumenanbieter
Charakteristik: Behauptet Expertise, optimiert aber für Volumen und Marge. Setzt Junior-Personal ein. Versagensmechanismus: „Wir haben SAP-Erfahrung“ ist technisch korrekt, aber irreführend. SAP für einen Einzelhändler ist etwas anderes als SAP für ein reguliertes Versorgungsunternehmen.
Typ 2: Der Systemintegrator ohne Domain-Wissen
Charakteristik: Kennt die Technologie, nicht die Branche. Versagensmechanismus: Technische Korrektheit ist nicht gleich Geschäftstauglichkeit.
Typ 3: Die Big-4-Firma mit Interessenkonflikt
Charakteristik: Berät, implementiert und prüft – manchmal beim selben Kunden. Das strukturelle Problem: Wer vom Folgegeschäft abhängt, hat keinen Anreiz, Probleme zu benennen.
Typ 4: Der Berater als „Partner des Managements“
Charakteristik: Sagt, was der Kunde hören will. Keine unabhängige Prüfung. Versagensmechanismus: Berater, die Probleme benennen, gefährden den nächsten Auftrag.
Wann externe Expertise tatsächlich wirkt
Die Analyse zeigt fünf kritische Erfolgsbedingungen:
1. Nachweisbare Referenzen im identischen Kontext
Nicht „ähnlich“, sondern identisch. SAP für ein US-Versorgungsunternehmen erfordert andere Expertise als SAP für einen europäischen Einzelhändler.
2. Trennung von Implementierung und Prüfung
Wer implementiert, kann nicht gleichzeitig unabhängig prüfen. Investieren Sie in unabhängige Qualitätssicherung als Versicherungspolice.
3. Geschäftsmodell, das Problemfindung belohnt
Ein Berater, dessen Auftrag es ist, Probleme zu finden, hat einen anderen Anreiz als ein Berater, dessen Folgeauftrag von zufriedenen Stakeholdern abhängt.
4. Seniorität ohne Team-Overhead
Das Problem großer Beratungshäuser: Seniors machen die Akquise, Juniors die Arbeit.
Gaps entstehen jeden Tag. Jede Schnittstelle, die nicht passt. Jeder Mitarbeiter, der geht. Jede Anforderung, die erst bei der Implementierung sichtbar wird.
Der Unterschied: Wenn unmögliche IT-Projekte doch gelingen
Referenzbeispiele aus der Praxis:
120 SAP-Systeme bei CIBER stabilisiert mit nur 4-Personen-Kernteam – als alle anderen aufgaben
Migration des Telekom-Kernnetzes (160 Millionen Verbindungen) – obwohl die Telekom sagte „unmöglich“
M/OMS Output Management System – 1988 entwickelt, nach 39 Jahren noch in Betrieb
Der Schlüssel: Unabhängige Senior-Expertise mit nachweisbarer Domain-Kontinuität, deren Geschäftsmodell die Identifikation von Problemen belohnt statt bestraft.
Fragen vor der Beauftragung
Bevor Sie externe IT-Expertise beauftragen, sollten Sie folgende Fragen beantworten:
Referenzen: Hat der Anbieter nachweisbare Erfahrung in exakt diesem Kontext?
Personal: Wer arbeitet tatsächlich am Projekt? Die Seniors aus dem Pitch oder ein Junior-Team?
Interessenkonflikt: Hängt der Anbieter vom Folgegeschäft ab?
Kontrolle: Wer behält die Projekthoheit? Gibt es eine unabhängige Prüfinstanz?
Accountability: Was passiert bei Versagen? Wie ist die Haftung geregelt?
Schlussfolgerung
IT-Projekte scheitern nicht, weil externe Expertise grundsätzlich versagt. Sie scheitern, weil:
Kostensenkung wichtiger ist als Qualifikation
Behauptungen nicht verifiziert werden
Kontrolle abgegeben wird
Interessenkonflikte ignoriert werden
Verträge keine Accountability erzwingen
Die dokumentierten Schäden – von 64 Millionen USD bei Revlon bis über 1 Milliarde USD bei National Grid – sind keine Naturkatastrophen. Sie sind das vorhersagbare Ergebnis vorhersagbarer Entscheidungen.
Die Frage ist nicht: Externe Expertise ja oder nein? Die Frage ist: Welche externe Expertise, unter welchen Bedingungen, mit welcher Accountability?
Wenn niemand traut sich ran und alle sagen „geht nicht“ – dann braucht es einen IT Troubleshooter Stuttgart, der gescheiterte Projekte retten, die unmögliche IT Migration möglich machen, Ihre IT-Krise lösen und unmögliche IT-Projekte realisieren kann – auch wenn McKinsey aufgibt.
Über den Autor
Michael Schmid ist Principal Consultant und Inhaber der it-dialog e.K. (gegründet 2000). Als Physiker mit über 40 Jahren IT-Erfahrung positioniert er sich als unabhängiger Experte für kontinuierliche Gap-Analyse in kritischen IT-Projekten.
Sein Ansatz unterscheidet sich von klassischer Beratung: Keine Implementierung, keine Teams, kein Folgegeschäft-Interesse. Stattdessen: Identifikation dessen, was nicht funktionieren wird – bevor die Millionen verbrannt sind.
Nehmen Sie Kontakt auf, wenn Sie vor unmöglichen IT-Projekten stehen: Kontakt | LinkedIn
Diese Studie basiert auf öffentlichen Gerichtsakten, Branchenstudien und dokumentierten Projektkatastrophen. Vollständige Quellenangaben auf Anfrage verfügbar.
Um dir ein optimales Erlebnis zu bieten, verwenden wir Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wenn du diesen Technologien zustimmst, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn du deine Zustimmung nicht erteilst oder zurückziehst, können bestimmte Merkmale und Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.